- 功能更新
- OurwayBI新框架v2.6发版说明(2025年07月25日)
- OurwayBI新框架v2.5发版说明(2025年03月25日)
- OurwayBI新框架v2.4发版说明(2024年11月0日)
- OurwayBI新框架v2.3发版说明(2024年7月04日)
- OurwayBI新框架v2.2发版说明(2024年3月13日)
- OurwayBI新框架v2.0发版说明(2023年9月27日)
- V8.11版本说明(2023年1月18日)
- V8.10小版本说明(2022年9月30日)
- V8.10版本说明(2022年6月23日)
- V8.9版本说明(2022年5月12日)
- V8.8版本说明(2022年4月15日)
- V8.7版本说明(2021年12月22日)
- V8.6小版本说明(2021年11月19日)
- V8.6版本说明(2021年11月11日)
- V8.5版本说明(2021年10月11日)
- V8.4版本说明(2021年8月09日)
- V8.4版本说明(2021年7月05日)
- V8.1版本说明(2021年3月12日)
- V8.1版本说明(2021年1月18日)
- V8.1版本说明(2020年12月04日)
- V8.1版本说明(2020年11月10日)
- V8.1版本说明(2020年9月30日)
- V8.1版本说明(2020年9月10日)
- V8.1版本说明(2020年8月21日)
- V8.1版本说明(2020年8月5日)
- V7.10版本说明(2020年6月23日)
- V7.10版本说明(2020年5月12日)
- V7.9版本说明(2020年3月31)
- V7.8版本说明(2020年3月24日)
- V7.7版本说明(2020年2月19日)
- V7.7版本说明(2020年1月9日)
- V8.8版本说明文档
- 系统安装部署
- 报表及管理驾驶舱开发
- 图表类型
- 图表对象应用
- 智能分析
- 大屏可视化&移动端
- ETL&数据填报
- 系统管理
- 部署集成
- 标准解决方案
- AI
- 指标管理
- 多语言
- 高手训练营
- 大屏展示文件夹
1.概述
1.1 前言
经过多年的信息化建设,各企事业单位都积累了海量的数据,并且这些数据还正以指数级增长,企业迫切需要对这些数据进行挖掘、清洗和处理,找出其背后的规律,准确把握企业的运营情况,从而进行科学决策,如果没有科学的数据分析和统计作依据,各项管理和决策就如同空中楼阁,虚而不实,然而在数据应用中,通常都会面临各种问题,比如:
各个业务系统相互独立,形成多个信息孤岛,数据共享存在困难;
业务系统中数据未得到有效整合,难以支撑数据的综合分析;
数据查询分析需要在多个系统中交叉进行,查询的效率及准确性低,对业务系统的负荷较高;
数据质量差,存在大量的“脏”数据;
数据不一致程度高,数据理解差异、口径不一等导致统计报表不一致;
历史数据遗失情况常见,对历史数据的分析难以进行;
未来数据的增长趋势明显,数据查询日趋复杂,业务系统难以适应企业的不断发展;
基于上述问题,为全面提升企业数据资源的开发利用水平,构建统一、集成、标准化的企业级数据平台势在必行。但是,在企业级数据平台的构建过程中,由于业务系统众多,数据来源复杂,其数据内容、数据格式和数据质量千差万别,数据集成、共享和标准化的难度较大,企业需要一个高效、敏捷、易用的平台完成对企业数据资源的梳理和有效集成,从而为企业的数据应用打下坚实的基础,这是增强企业竞争力的必然选择。
2.产品说明
目前,数据整合类产品大多属于代码生成类工具,即采用可视化开发界面,通过拖拽设置各种数据处理组件来组成数据流和任务控制流,从而代替手写代码的方式,并依据自身的数据处理引擎来完成数据的加工处理,多数采用客户端开发+服务器运行的模式。这类产品功能丰富、架构复杂,在提供强大功能的同时也带来一些不便,如学习曲线较长、蛛网式组件开发调试困难、系统部署繁琐、监控及运维不便、实施周期过长、产品价格过高等等。这些过于复杂的重量级 ETL 产品让很多想开展数据整合工作的用户望而却步,目前市场上急需一种适合敏捷开发、轻松运维、价格合理的轻量级数据整合工具。
奥威ETL平台正是定位于这样一款轻量级数据整合类工具软件,具有开发容易、部署简单、运维轻松的特点,产品采用先抽取加载到目标数据库后再进行清洗转换的 ELT 方式,充分利用数据库服务器自身的性能优势,通过异构数据采集、转换脚本任务、作业控制流、计划调度、实时监控等核心服务引擎,开发人员只需要掌握基本的 SQL 语言就可以准确、高效的实现企业内数据整合的开发工作,为企业提供包括数据迁移、数据标准化、数据同步、数据交换、数据仓库在内的一体化数据整合服务。
3.ETL概念
ERP数据源:各类ERP的账套、数据存放的实体
DW:数据仓库,将各个ERP的数据打通后保存的地方。
ETL:Extraction-Transformation-Loading的缩写,中文名称为数据提取、转换和加载 ,从ERP数据库,抽取所需数据到DW的过程。
SQL任务:仅在同一个数据源中进行数据操作,比如一个删除的任务,如下图所示,选择任务类型为SQL任务,数据源为 需要在此数据源上进行的操作(一般是数据仓库),事务类型一般默认。
数据流任务:在两个数据源之间进行数据的抽取,比如需要 数据源(ourwaytes_yxw)中脚本中的查询结果 抽取到 目的数据源中(yxwmysql)的 目的表(f_trans_bills_temp)
增量【按月】【按年】【按日】是系统自有的参数
增量年:比如当前时间是2019年7月26日时,选择增量年,
数值输入0,则增量就是从2019年1月1日【当年】
如果输入1,就是从2018年1月1日开始,
如果输入是2,则是从2017年1月1日开始。
增量月:当前时间是2019年7月26日时,选择增量月,
数值输入0,则增量就是从2019年7月1日【当月】,
如果输入1,就是从2019年6月1日开始,
如果输入是2,则是从2019年5月1日开始。
增量日:当前时间是2019年7月26日时,选择增量日,
数值输入0,则增量就是从2019年7月26日【当日】,
如果输入1,就是从2019年7月25日开始,
如果输入是2,则是从2019年7月24日开始
4.ETL界面说明
登录系统后,点击ETL设置进入ETL界面,如下图所示.png)
ETL首页主要分为3部分,分别为模块的快速链接、调度计划列表和计划执行日志分析,如下图所示.png)
4.1 数据资源
数据资源包括数据连接、驱动管理、变量管理.png)
数据源广泛支持各种带有 JDBC 驱动的关系型数据库、MPP 数据库以及 EXCEL、CSV 等格式的文本数据,除预置的各种数据库驱动外,用户还可以自己添加维护新的数据库类型。
数据资源模块的主要功能包括源与目标的数据连接方式设置、表结构管理以及变量管理等。
4.1.1 数据连接
注意:1、新装的BI,需要配置java环境(jdk1.8版本)才可使用数据连接,否则会连接不上,jdk版本不正确也会导致连接失败,请确保在连接之前已配置好java环境。
数据链接建立源和目标的各种数据连接,依据预先设置的数据驱动模板进行配置。数据连接采用 JDBC 方式,配置完成后可通过连接测试进行正确性验证。此页面主要分为4个模块,如下图。.png)
(1)新建连接.png)
连接类型:驱动模板中已包含的数据库类型;
连接名称:自定义数据连接的名称;
描述:数据连接的描述信息;
主机:服务器的名称或 IP 地址;
端口号:数据库服务端口号;
数据库/模式:数据库名称或模式(Catalog 或 Schema)名称,对 Oracle 而言此处是服务名(SID);
用户名:数据库用户名;
密码:用户名对应的密码;
最大连接数:用户可结合网络、数据连接的数据库类型选择合适的大小进行填写;
JDBC串:系统根据驱动模板和数据连接的输入内容自动创建 JDBC 连接串,对于一些驱动中的特殊属性,可以自己手工配置 JDBC 连接串;
测试连接:根据配置信息测试连接数据源;
(2)编辑和删除连接
当鼠标滑过数据连接名称时,出现编辑和删除按钮,用户可选择对应的按钮进行操作。.png)
(3)导入元数据
为了限定数据转换中用到的表的范围,并便于在数据转换任务中选择表和字段,系统支持将数据源中的表结构导入进来不会将表中原始数据导入进来),并可对表中数据进行预览。.png)
(4)查看元数据
点击查看按钮之后,可出现详细信息,此信息只允许用户查看,不能进行修改。.png)
(5)Excel数据源
连接类型选”EXCEL”,将excel文件拖拽至下方区域或者点击区域选择文件上传。
注意:
上传的excel文件必须符合规则(如下说明),否则导表会失败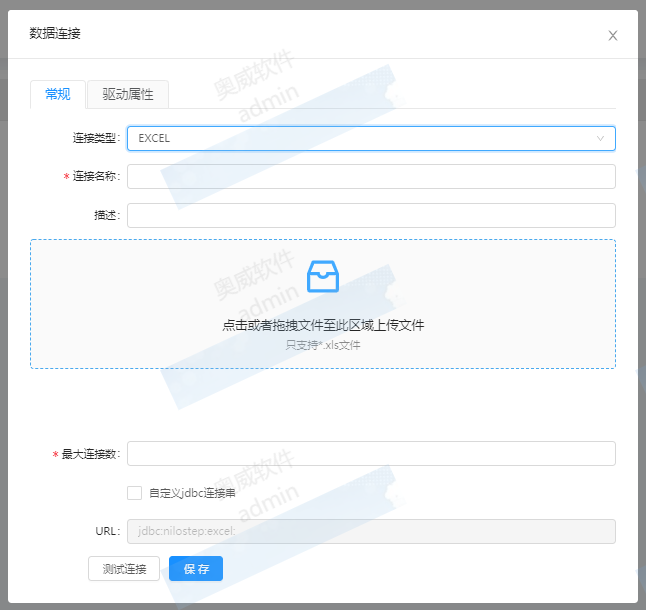
说明:
excel内容格式要求第一行为列名称,起始列从第一列A开始.png)
4.1.2 驱动管理
对数据驱动的模板配置信息进行维护,用于新增一种新数据驱动的模板,也可以修改默认数据驱动的模板配置,此页面主要分为三部分,如下图。
(注:当前软件支持咱们国产数据库如大金仓和达梦)
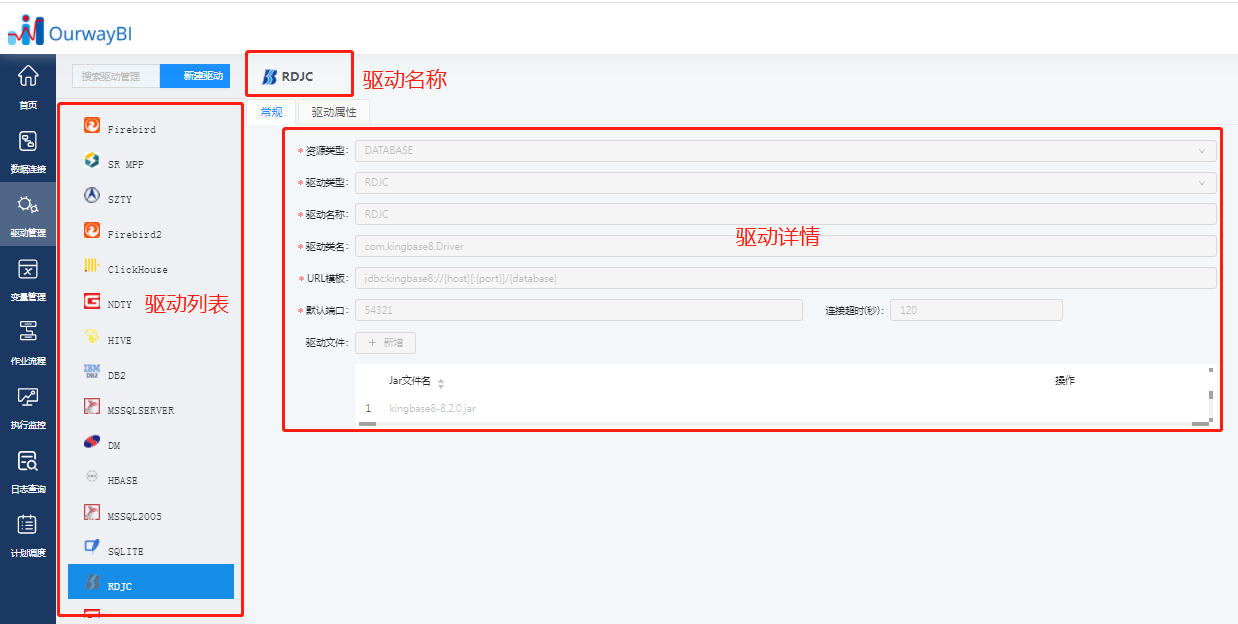
(1)新建驱动.png)
资源类型:包括数据库、平面文件、SAP ECC 系统、OLAP 多维数据库 4 种类型。
驱动类型:系统预置的数据库类型,新建其它未预置的数据库驱动时选择 Other 选项。
驱动名称:可自定义驱动名称。
驱动类名:JDBC 驱动 Jar 文件的类名,此名称可通过查询该驱动的相关文档获得。
URL 模板:JDBC 连接串的模板,模板中可以嵌入变量以动态替换用户设置的值,包括:
{host} :主机名或 IP 地址
{port} :端口号
{database} :数据库名称
[ ] :表示为可选项内容
默认端口:该数据库驱动的默认端口号。
连接超时:连接数据库时超过该时长仍未连接成功将停止连接。
驱动文件:通用的驱动会初始化,其他需用户根据实际情况进行导入即可。
注意:
1) 驱动名称、驱动类名以及URL模板不可输入空格以及字符“”;
2) 默认端口和连接超时需输入数字;
3) 驱动文件只可导入.jar类型的文件;
4) 文本框会记录用户之前输入的信息进行选择,若不需要,清除浏览器缓存即可。
(2)编辑驱动
注意:重置按钮只重置保存之后修改的内容,一旦保存,重置按钮无效;.png)
(3)删除驱动
当鼠标滑过驱动名称时,点击删除按钮,即可删除该驱动。.png)
4.1.3 变量管理
变量管理是为了用户方便操作,在此页面可新增变量,用户再使用该变量仕,直接插入即可。
(1)新增变量.png)
变量名称:自定义变量名称;
描述:该变量的描述信息;
变量类型:该变量的类型,可以自定义变量,也可以使用系统变量(增量年、增量月、增量天);
默认值:该变量默认值;
(2)修改变量
点击要修改的变量一行中的修改按钮,弹出修改变量的详细弹框,可直接修改保存即可。.png)
(3)删除变量
点击要删除的变量一行中的删除按钮,弹出删除变量的详细弹框,确认后即可删除该变量。.png)
(4)搜索变量
用户可输入变量名称和变量描述的信息,点击搜索按钮或按下回车键进行搜索,此搜索是模糊搜索。.png)
(5)变量排序
为方便用户查看以及编辑变量,用户可点击列名进行排序显示。.png)
(6)计算变量
可点击“计算变量”,即可知道设置的该变量的值是多少。.png)
4.2 作业流程
4.2.1 新建文件夹
左边的作业流列表默认只有“主文件夹”,用户可以右击新建文件夹,输入文件名称和对此文件的描述,点击“确认”即可新建完成。.png)
注意:文件夹名称不可重复、不可输入特殊字符“”以及空格。.png)
4.2.2 新建作业流
用户可以点击“新建流程”,输入相应的信息进行确认即可。新建的作业流会自动增加一个START节点.png)
选择作业流程会出现相对应流程节点.png)
选择刚才创建好的作业流后,会出现工具栏以及绘图区域,从左侧的组件栏中鼠标点击并拖放相应的组件到右边的画布区域。.png)
作业组件:平台为用户提供了三种作业组件,即三种转换任务。拖放此模块的节点为新增节点。
当前节点:当前流程图所有的节点,拖放此模块节点为复制该节点
所有节点:此用户下所有作业流的节点但不包括START节点,拖放此模块的节点为引用或复制。
新增:增加一个新的节点
复制:节点存在当前流程图叫复制,复制则是复制它的节点及明细信息。
引用:节点不存在当前流程图叫引用,引用则是一个明细修改,所有引用的明细都会被修改。
添加连线
点击源节点的锚点(节点上的绿色图标),然后再点击目标节点,会在两个节点间创建一条连线,点击连线或通过连线的右键菜单可以更改连线的状态。连线的状态有 4 种:
成功(绿色):节点执行成功或条件判断为真时执行下一节点。
错误(红色):节点执行出错或条件判断为假时执行下一节点。
无条件(蓝色):节点执行成功或出错都无条件的执行下一节点。但如果是手工中断时,则停掉后续任务的执行。
失效(灰色):连线设为失效后,后续路径不再执行。
连线的类型也可以通过右键菜单更改,类型包括3种:曲线、直线和折线。
.png)
.png)
.png)
执行监控:包括执行监控、日志查询
计划调度:包括文件夹与新建计划
5.应用场景
ETL:Extraction-Transformation-Loading的缩写,中文名称为数据提取、转换和加载 ,从ERP数据库,抽取所需数据到DW的过程。
6.ETL操作流程图.png)
7.ETL实例演示
7.1 创建目的表与中间表
现在需要将MSSQL中的商品、品类等数据抽取到MYSQL的数据仓库中,所以先提前在MYSQL数据仓库中创建好相关的表。为了表示更好理解,这边创建表格只取核心字段(如ID,名称,分类ID)
以下创建脚本在MYSQL数据仓库中执行或者通过一个SQL任务来创建
商品目的表
drop table if exists d_goods;
create table d_goods
(
fid int,
fname nvarchar(150),
fclassid int
);
商品中间表
drop table if exists d_goods_temp;
create table d_goods_temp
(
fid int,
fname nvarchar(150),
fclassid int
);
商品品类目的表
drop table if exists d_goodsclass;
create table d_goodsclass
(
fid int,
fname nvarchar(150),
fparentid int
);
商品品类中间表
drop table if exists d_goodsclass_temp;
create table d_goodsclass_temp
(
fid int,
fname nvarchar(150),
fparentid int
);
门店表
drop table if exists d_department;
create table d_department
(
departmentid int,
departmentname nvarchar(150),
departmentclassid int
);
门店中间表
drop table if exists d_department_temp;
create table d_department_temp
(
departmentid int,
departmentname nvarchar(150),
departmentclassid int
);
区域表
drop table if exists d_departmentclass;
create table d_departmentclass
(
departmentclassid int,
departmentclassname nvarchar(150),
parentid int
);
区域中间表
drop table if exists d_departmentclass_temp;
create table d_departmentclass_temp
(
departmentclassid int,
departmentclassname nvarchar(150),
parentid int
);
事实表(销售流水账)
drop table if exists f_sale;
create table f_sale
(
fbillno varchar(150),– 编码
fitemid int , — 商品ID
fdeptid int , — 门店ID
fdate datetime, — 单据日期
fqty int , — 数量
famount decimal(20,3), — 销售金额
fcost decimal(20,3),– 销售成本
fprice decimal(20,3) — 销售单价
);
事实表中间表(销售流水账)
drop table if exists f_sale_temp;
create table f_sale_temp
(
fbillno varchar(150),– 编码
fitemid int , — 商品ID
fdeptid int , — 门店ID
fdate datetime, — 单据日期
fqty int , — 数量
famount decimal(20,3), — 销售金额
fcost decimal(20,3),– 销售成本
fprice decimal(20,3) — 销售单价
);
在MYSQL中执行成功.png)
7.2 创建数据源
(1)点击数据源连接.png)
(2)进入数据源连接界面添加数据来源库.png)
.png)
(3)同样的方法,再把数据仓库添加进来.png)
7.3 导入元数据
(1)先选择sql数据源,点击批量导入,选择需要用到的来源表勾选,点击确定.png)
(2)如此操作批量导入表:商品表(goods)、品类表(goodsclass)、门店表(department)、区域表(departmentclass)、销售流水表(ICstockbill),效果如图.png)
(3)相同操作,选择数据仓库导入相关的中间表与目的表
商品表(d_goods)、商品中间表(d_goods_temp),品类表(d_goodsclass)品类中间表(d_goodsclass_temp)、门店表(d_department)、门店中间表(d_department_temp)区域表(d_departmentclass)、区域中间表(d_departmentclass_temp)、销售流水表(f_sale),销售流水中间表(f_sale),效果如图.png)
7.4 新建流程
(1)点击作业流程进入流程界面,右键点击主文件夹,新建一下销售文件夹用来存放作业流程,如下图.png)
(2)点击新建流程,输入流程名称、并选择文件夹、点击确定.png)
删除任务:删除中间表的历史数据
(3)打开销售文件夹,选择流程在作业组件中添加任务,选中SQL任务并拖动到展示界面,如下图所示 .png)
(4)选中SQL任务,双击或右键打开编辑,在基本信息输入任务名称 .png)
(5)在脚本定义中选中数据库为创建的数据仓库,执行方式选择执行sql代码块,在脚本下方输入删除中间表的脚本,输入完成后点击确定。如下图所示.png)
(6)删除脚本:
truncate table d_goods_temp;
truncate table d_goodsclass_temp;
truncate table d_department_temp;
truncate table d_departmentclass_temp;
抽取数据任务:从客户的数据源把需要的数据抽取到中间表
(7)同样操作,添加数据流任务,在基本信息界面添加任务名称 .png)
(8)点击源,输入如图信息 .png)
(9)点击目标,输入如图所示信息.png)
(10)点击字段映射,输入如下信息.png)
商品抽取脚本:
select goodsid as fid,goodsname as fname,goodsclassid as fclassid from goods
品类抽取脚本:
select goodsclassid as fid,goodsclassname as fname,parentid as fparentid from goodsclass
区域抽取脚本:
select departmentclassid as departmentclassid,departmentclassname as departmentclassname,parentid as parentid from departmentclass
门店抽取脚本:
select departmentid as departmentid,departmentname as departmentname,departmentclassid as departmentclassid from department
插入任务:把抽取的数据从中间表抽到目的表
(11)同样操作,添加一个SQL任务,输入如下信息.png)
.png)
(12)插入目的表脚本:
商品表
truncate table d_goods;
insert into d_goods(fid,fname,fclassid)
select fid,fname,fclassid from d_goods_temp ;
品类表
truncate table d_goodsclass;
insert into d_goodsclass(fid,fname,fparentid)
select fid,fname,fparentid from d_goodsclass_temp ;
区域表
truncate table d_departmentclass;
insert into d_departmentclass(departmentclassid,departmentclassname,parentid)
select departmentclassid,departmentclassname,parentid from d_departmentclass_temp ;
门店表
truncate table d_department;
insert into d_department(departmentid,departmentname,departmentclassid)
select departmentid,departmentname,departmentclassid from d_department_temp ;
(13)对任务进行连线,如下图所示从START开始,先清除历史数据任务—再到抽取数据任务–插入数据任务.png)
(14)同样的方法,添加完基础资料后增加事实表流程,并对事实表(销售流水账)进行添加任务,如下图所示.png)
(15)清理中间表脚本:
delete from f_sale_temp;
(16)抽取事实表脚本:
提取销售单据数据
select fdate as fdate, orderid as fbillno,goodsid as fitemid,departmentid as fdeptid,totaldecimal as famount,totalmoney as fcost,quantity as fqty,saleprice as fprice from ICstockbill
插入目的表脚本:
delete from f_sale;
insert into f_sale(fdate,fbillno,fitemid,fdeptid,famount,fcost,fqty,fprice) select fdate,fbillno,fitemid,fdeptid,famount,fcost,fqty,fprice from f_sale_temp;
7.5 执行监控
(1)添加完任务后,点击执行监控.png)
(2)在执行监控界面选择基础资料流程,点击执行按钮 .png)
(3)选择执行方式,从某点开始选择从START开始,点击执行.png)
(4)执行完毕后,会显示出执行的结果详细信息,如下图所示 .png)
执行成功后,在数据库可查询到数据.png)