- 功能更新
- OurwayBI新框架v2.6发版说明(2025年07月25日)
- OurwayBI新框架v2.5发版说明(2025年03月25日)
- OurwayBI新框架v2.4发版说明(2024年11月0日)
- OurwayBI新框架v2.3发版说明(2024年7月04日)
- OurwayBI新框架v2.2发版说明(2024年3月13日)
- OurwayBI新框架v2.0发版说明(2023年9月27日)
- V8.11版本说明(2023年1月18日)
- V8.10小版本说明(2022年9月30日)
- V8.10版本说明(2022年6月23日)
- V8.9版本说明(2022年5月12日)
- V8.8版本说明(2022年4月15日)
- V8.7版本说明(2021年12月22日)
- V8.6小版本说明(2021年11月19日)
- V8.6版本说明(2021年11月11日)
- V8.5版本说明(2021年10月11日)
- V8.4版本说明(2021年8月09日)
- V8.4版本说明(2021年7月05日)
- V8.1版本说明(2021年3月12日)
- V8.1版本说明(2021年1月18日)
- V8.1版本说明(2020年12月04日)
- V8.1版本说明(2020年11月10日)
- V8.1版本说明(2020年9月30日)
- V8.1版本说明(2020年9月10日)
- V8.1版本说明(2020年8月21日)
- V8.1版本说明(2020年8月5日)
- V7.10版本说明(2020年6月23日)
- V7.10版本说明(2020年5月12日)
- V7.9版本说明(2020年3月31)
- V7.8版本说明(2020年3月24日)
- V7.7版本说明(2020年2月19日)
- V7.7版本说明(2020年1月9日)
- V8.8版本说明文档
- 系统安装部署
- 报表及管理驾驶舱开发
- 图表类型
- 图表对象应用
- 智能分析
- 大屏可视化&移动端
- ETL&数据填报
- 系统管理
- 部署集成
- 标准解决方案
- AI
- 指标管理
- 多语言
- 高手训练营
- 大屏展示文件夹
1.爬虫场景与需求
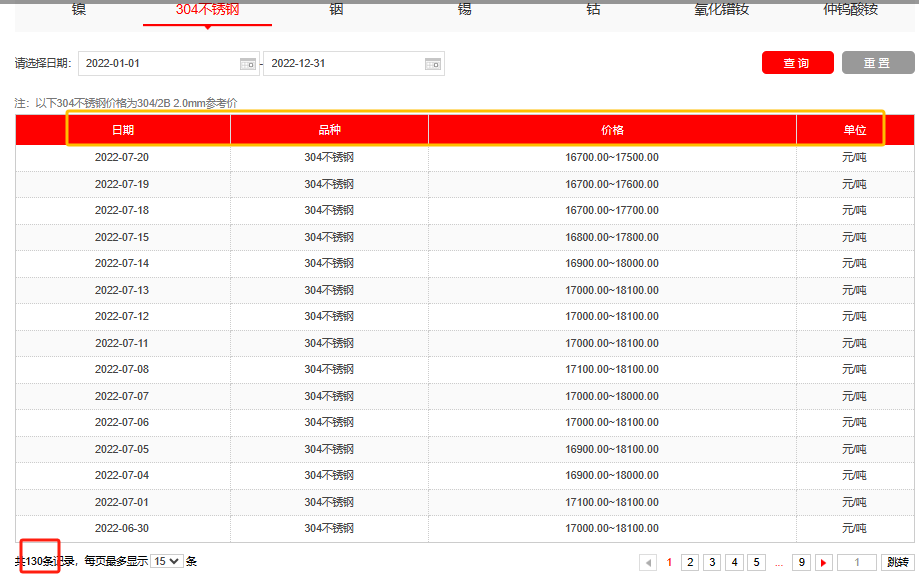
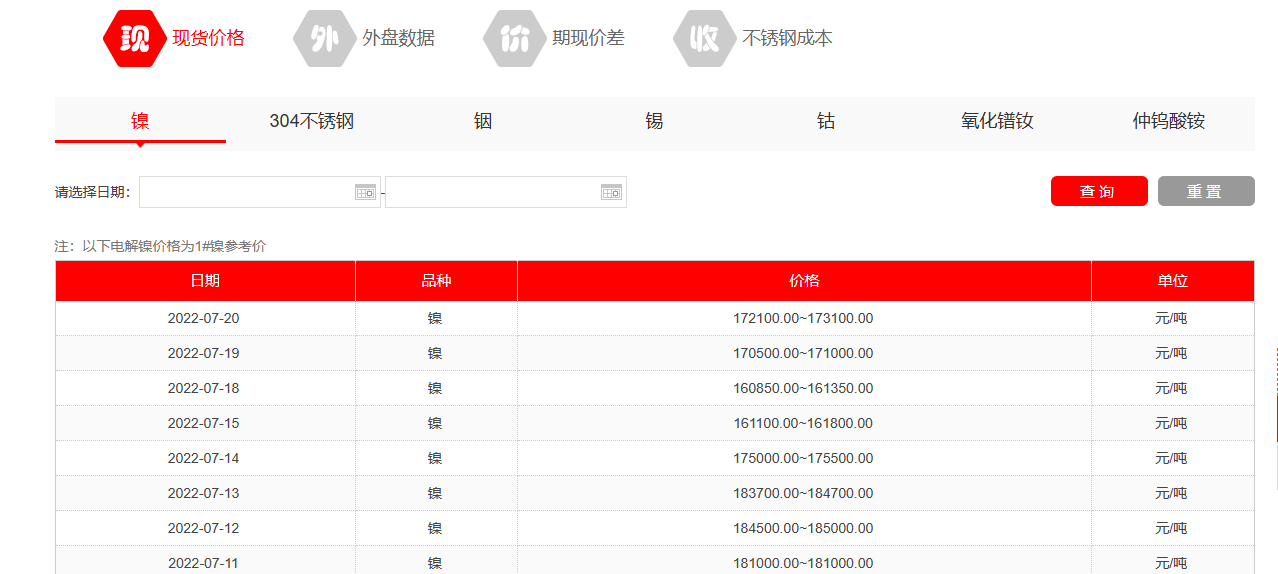
设计一个爬取数据的任务,目标是从某网站,获取到2022年304不锈钢的现货价格记录。
1.1 确认设计流程
访问网页-选取材料类型-输入起始日期-输入结束日期-点击查询-获取表头(数据类型)-获取表列数据-翻页(循环)直至每页的数据抽取完成
1.2 爬虫流程设计
(1)创建爬虫任务
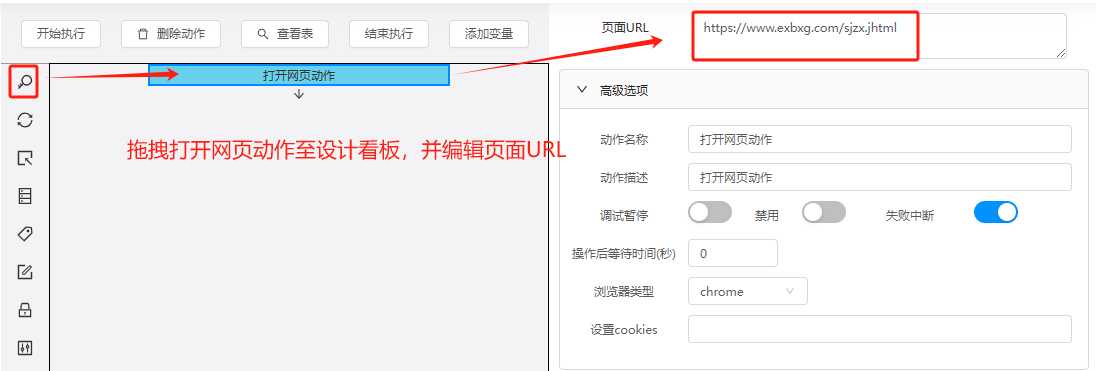
(2)打开网页
拖拽打开网页动作至设计看板,并录入访问网页的页面URL。
参考地址:https://www.exbxg.com/sjzx.jhtml
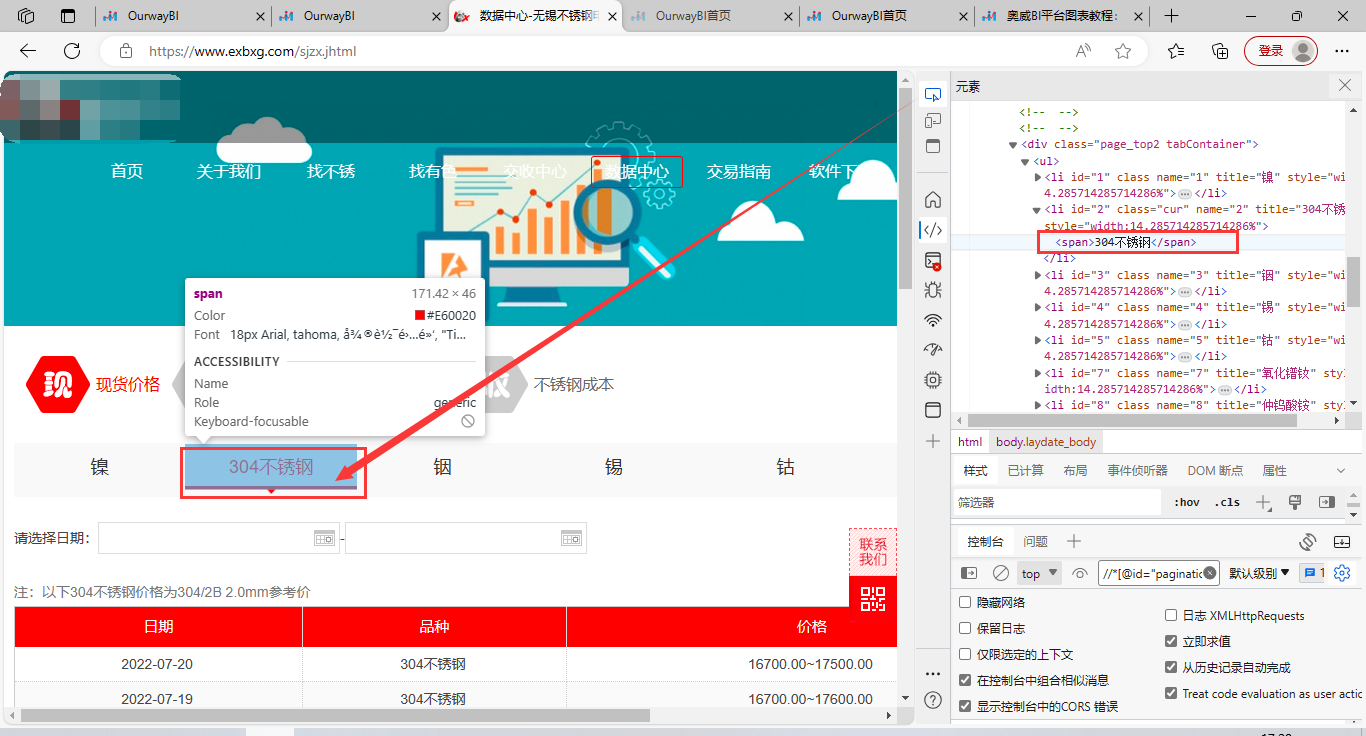
(3)选择材料类型
拖拽点击动作至设计看板,形成流程,并完善动作名称和点击路径。
路径获取方式:
①在对应网页上,按F12弹出开发者工具。
②点击选择和跟踪元素按钮(快捷键:Ctrl+Shift+C),并点击需要获取路径的元素,右侧窗口即可定位到对应元素。
③选择相应元素,右键复制-选择复制XPath或复制完整的XPath。
④将获取到的Xpath路径粘贴到爬虫动作的路径。
参考路径:/html/body/div[2]/div[2]/div[2]/ul/li[2]



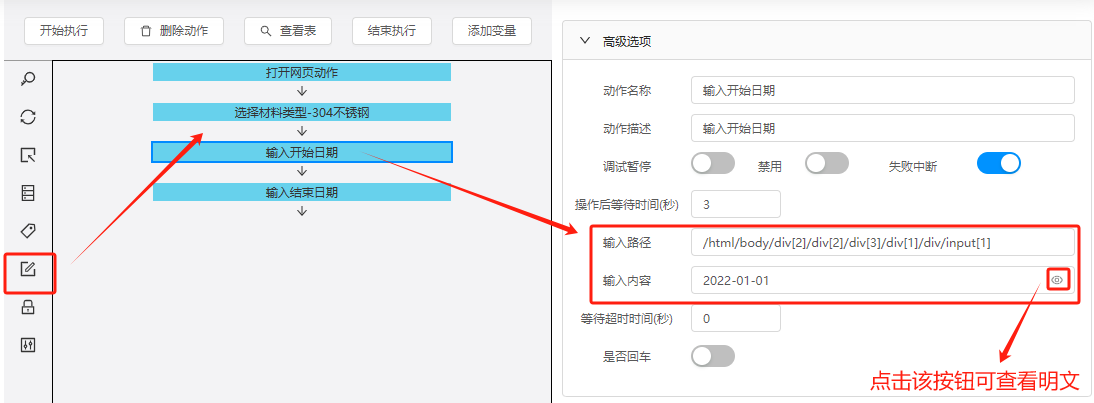
(4)输入开始日期/结束日期
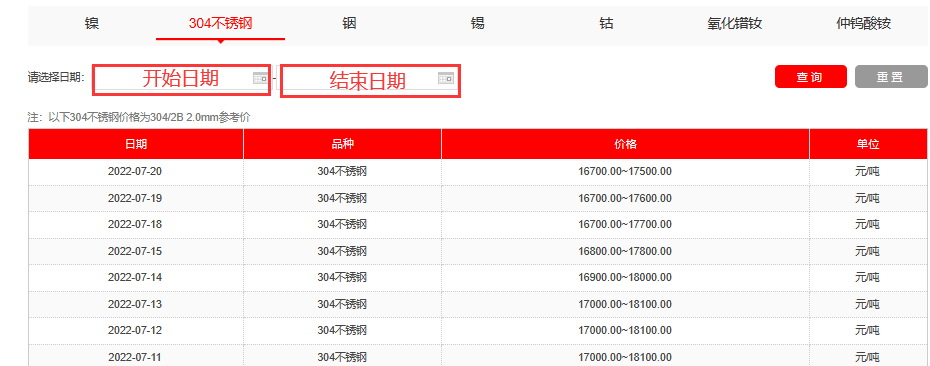
拖拽输入动作至设计看板,形成流程,并完善动作名称和点击路径。
开始日期参考路径:/html/body/div[2]/div[2]/div[3]/div[1]/div/input[1]
结束日期参考路径:/html/body/div[2]/div[2]/div[3]/div[1]/div/input[2]
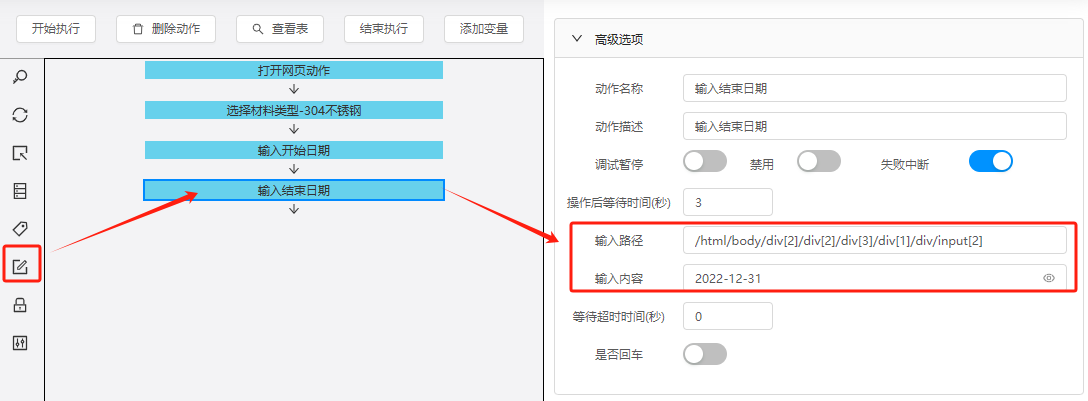
(5)点击查询
拖拽点击动作至设计看板,形成流程,并完善动作名称和点击路径。
参考路径:/html/body/div[2]/div[2]/div[3]/div[2]/div[1]/button

(6)设置循环动作
添加循环动作,循环类型设置为翻页点击循环,下一页的翻页路径来源如图所示。

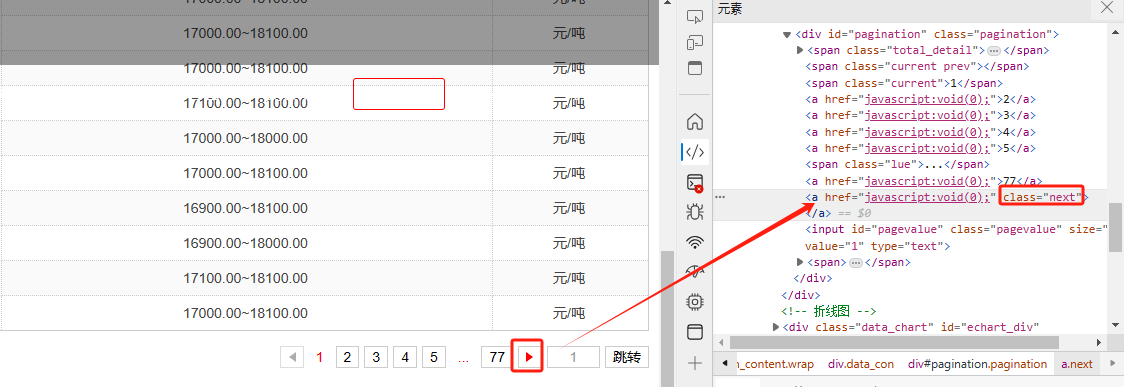

根据来源代码中属性的类别和其名称,添加后缀[contains(@class,"next")]
参考路径://*[@id="pagination"]/a[contains(@class,"next")]

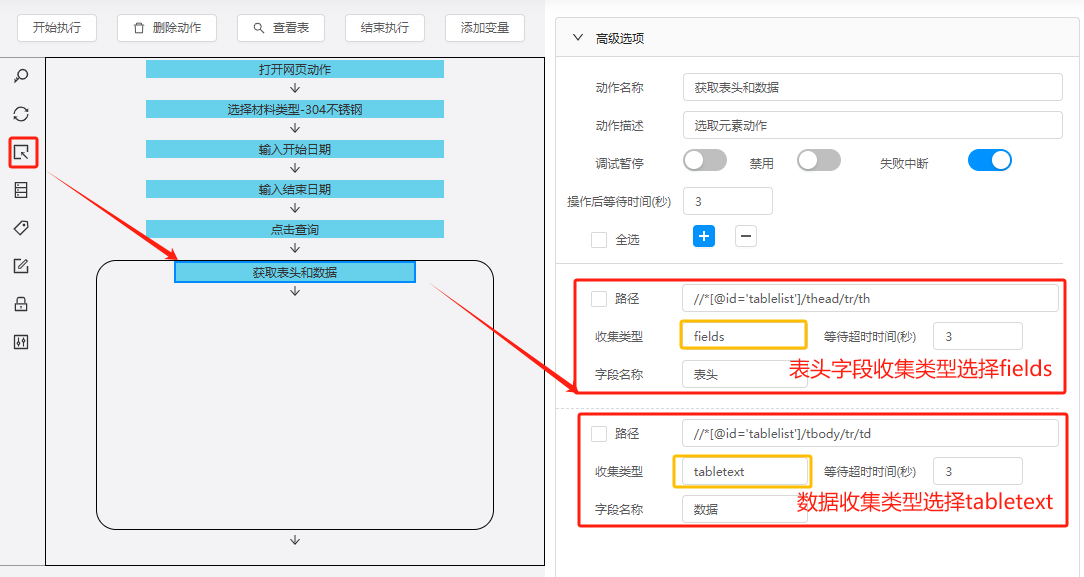
(7)获取表头和数据
添加选取元素动作至循环动作内,获取表头和数据,采集路径需要进行加工,并调整字段类型。
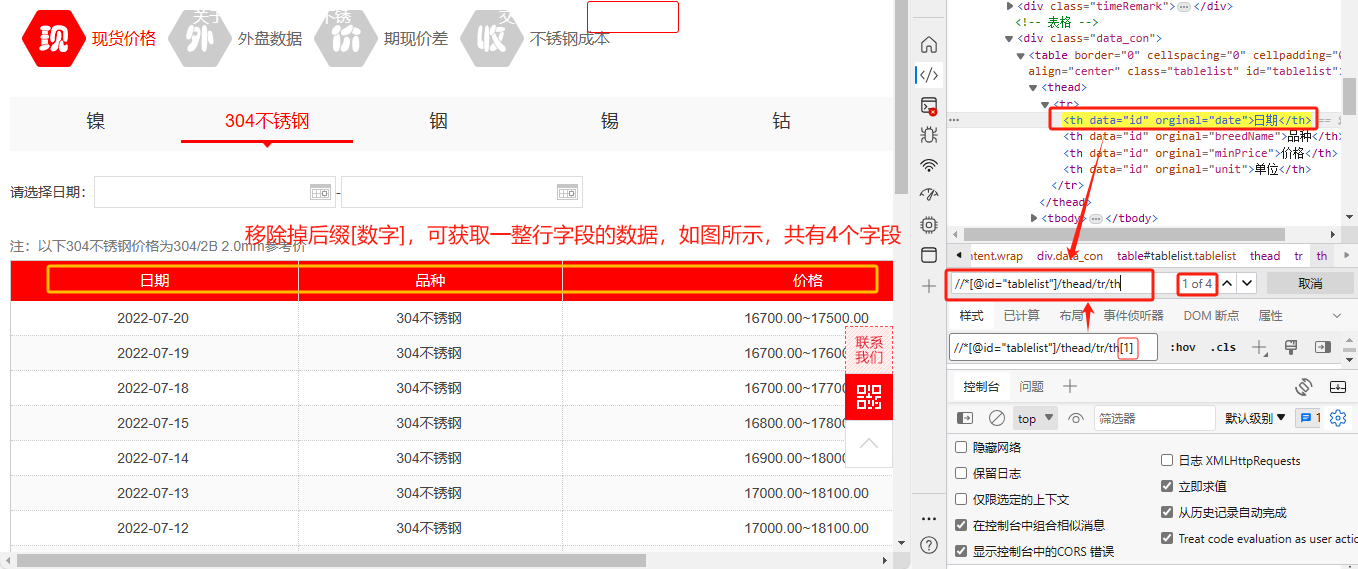
表头:将采集路径中的后缀”[数字]“移除掉,收集类型选择fields。
参考路径://*[@id='tablelist']/thead/tr/th
数据:将采集路径中的tr和td的后缀”[数字]“均移除掉,收集类型选择tabeltext。
参考路径://*[@id='tablelist']/tbody/tr/td

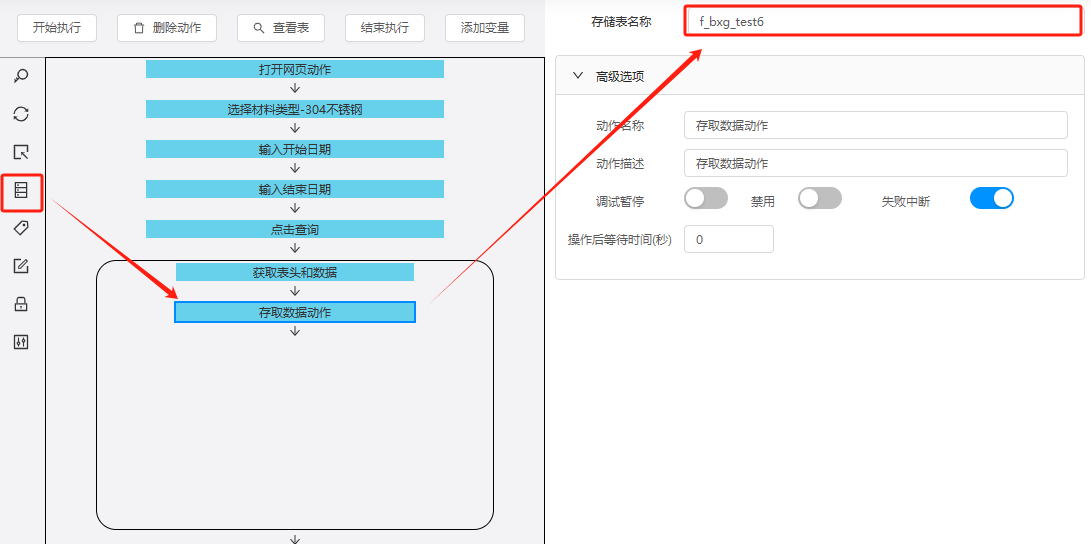
(8)存取数据动作
添加存取数据动作至循环动作内,将采集的数据写入到存储表中。
1.3 执行爬虫
(1)点击执行
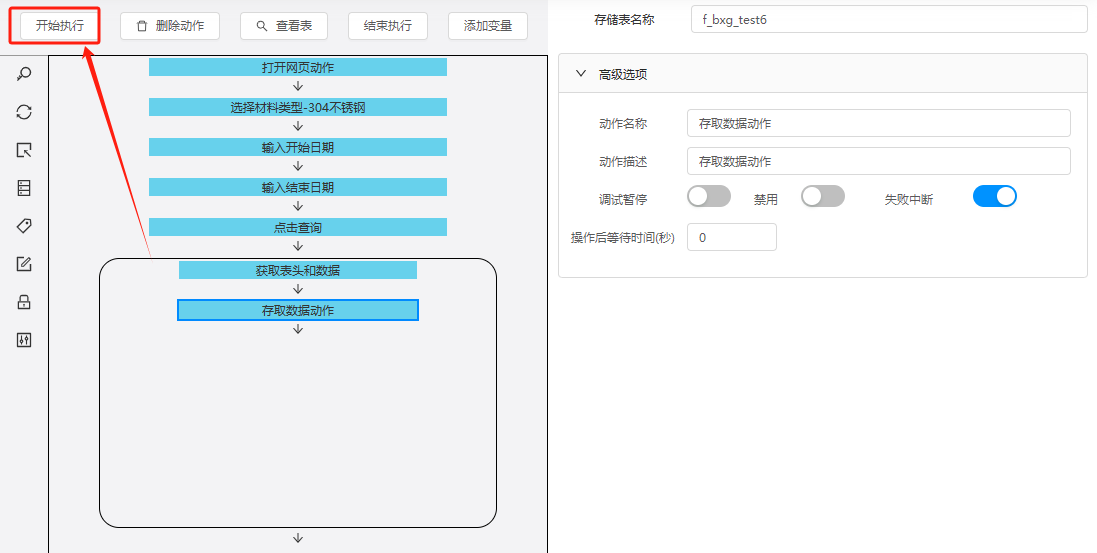
(2)查看表数据
执行成功,点击完成,并查看表数据,验证循环次数符合实际页数,采集的数据行和列没有缺漏,完成外部数据的循环爬取任务。